Вы сможете спрогнозировать продажи, не прибегая к сложным формулам, рассчитать коридор спроса, определив верхнюю и нижнюю границы будущих продаж, использовать универсальный метод прогноза продаж для любого периода.
Вместо громоздких формул для прогноза спроса на продукцию мы используем один график в Excel, который строим исходя из данных о продажах компании. Алгоритм вывели самостоятельно, опираясь на советы знакомых бизнесменов и материалы из интернета. С помощью графика прогнозируем продажи на месяц, несколько месяцев или год. Чтобы повторить опыт, вам потребуется версия Excel 2003–2016 года. Кроме того, в конце статьи вы найдете альтернативный способ, который позволит построить прогноз за несколько минут. Однако он подходит исключительно для версии Excel 2016 года.
Чтобы приступить к анализу, вам понадобятся данные о продажах компании за весь период ее существования. Чем больше информации, тем точнее прогноз. У нас, к примеру, есть сведения о продажах с января 2013 года по август 2015-го. Заносим их в таблицу (рисунок 1).
Мы подготовили статью, которая:
✩покажет, как программы слежения помогают защитить компанию от краж;
✩подскажет, чем на самом деле занимаются менеджеры в рабочее время;
✩объяснит, как организовать слежку за сотрудниками, чтобы не нарушить закон.
С помощью предложенных инструментов, Вы сможете контролировать менеджеров без снижения мотивации.
Чтобы спрогнозировать продажи, к примеру, на месяц или на будущий год, используем функцию «ПРЕДСКАЗ» в Excel. Функция основана на линейной регрессии и предназначена для прогнозирования продаж, потребления товара и пр.
В ячейку C34 записываем функцию:
ПРЕДСКАЗ(x; известные_значения_у; известные_значения_х),
х - дата, значение для которой необходимо предсказать (ячейка A34);
Чтобы учесть сезонные спады и рост продаж, с помощью стандартных функций вычисляем коэффициент сезонности. Для этого суммы продаж за первый и второй год делим на общую сумму продаж за два года и умножаем на 12. С помощью клавиши F4 устанавливаем абсолютные ссылки, чтобы расчет шел исключительно из нужного нам диапазона (рисунок 1).
=(($B$2:$B$13+$B$14:$B$25)/СУММ($B$2:$B$25))*12
Далее копируем формулу и вставляем в ячейки F2:F13 как формулу массива. Завершаем ввод сочетанием клавиш: Ctrl+Shift+Enter. Если этого не сделать, функция вернет значение ошибки #ЗНАЧ! В результате для января получим коэффициент 0,974834224106574, для февраля - 0,989928632237843 и т. д. Для наглядности можно назначить ячейкам процентный формат. Правой кнопки мыши выбираем «Формат ячеек», затем вкладку «Число» и далее вкладку «Процентный, два знака после запятой».
Добавим рассчитанные коэффициенты в имеющуюся функцию «ПРЕДСКАЗ» (ячейки C34:C45):
Чтобы скорректировать продажи, учитывая коэффициент, используем функцию «ИНДЕКС» (рисунок 2).

Первым аргументом в функции указываем ссылку на 12 ячеек с коэффициентами сезонности ($F$2:$F$13), вторым - номер месяца, чтобы вернуть коэффициент для нужного месяца (для этого используем функцию «месяц», которая возвращает только номер месяца из указанной даты). Для сентября 2015 года формула индекса выглядит так:
ИНДЕКС($F$3:$F$14;МЕСЯЦ(A35))
Чтобы скорректировать прогноз, нужно значение «ИНДЕКС» умножить на значение «ПРЕДСКАЗ», которое рассчитывали в шаге 2. Вот что мы получим:
ПРЕДСКАЗ(A34; $B$2:$B$33; $A$2:$A$33)*ИНДЕКС ({97,48%:98,99%:90,38%:94,66%:100,86%:99,02%:100,66%:110,39%:100,47%:104,82%:105,13%:97,14%}; 9)
Распространяем функцию на дальнейшие периоды и получаем скорректированный прогноз с учетом сезонности в ячейках C34:С45 (рисунок 1).
Реальные продажи редко в точности соответствуют прогнозам. Поэтому компании дополнительно строят допустимые верхние и нижние границы - прогноз продаж по оптимистичному и пессимистичному сценариям. Это помогает отследить тенденцию и понять, выходят ли реальные показатели продаж за спрогнозированные значения. При большом отклонении можно в срочном порядке принять необходимые меры.
Верхние и нижние границы коридора спроса строим по формуле (ячейка G2 на рисунке 1):
ДОВЕРИТ(0,05 (АЛФА); СТАНДОТКЛОН(C34:C45); СЧЕТ(C34:C45)),
«ДОВЕРИТ» возвращает доверительный интервал, используя нормальное распределение. Функция учитывает колебания продаж компании, включая сезонные.
«АЛФА» - уровень значимости для вычисления доверительного уровня. Показатель 0,05 означает, что мы получим прогноз с точностью 95%.
«СТАНДОТКЛОН» - стандартное отклонение генеральной совокупности. Показывает, насколько прогнозируемые продажи отличаются от реальных.
«СЧЕТ» подсчитывает количество месяцев, по которым мы прогнозируем продажи.
Чтобы получить оптимистичный и пессимистичный сценарии, в ячейки D34 и D35 записываем формулы (рисунок 1).
Оптимистичный: =$C34+$G$2 (прибавляем к сумме прогноза сумму рассчитанного доверительного интервала)
Пессимистичный: =$C34–$G$2 (вычитаем из суммы прогноза сумму доверительного интервала)
Чтобы по полученным данным построить график, в ячейки C33, D33 и E33 копируем значения из ячейки B33. Далее выделяем все данные (A1:E45), переходим на вкладку «Вставка», находим вкладку «Диаграммы» и затем вкладку «График». В итоге получаем график с коридором спроса (рисунок 3).

Вывод. Построив коридор спроса, внимательно следим за продажами в новом году. В 99 % случаев они развиваются в рамках коридора. Если нет - анализируем продажи еще раз и строим новый график.
Мнение эксперта
Максим Люлин,
генеральный директор «Актион-пресс»
Я бы советовал использовать метод для прогноза в отношении одного артикула - тогда он будет максимально точным. В целом метод понравился мне своей простотой и тем, что позволяет избежать ошибок. Его также можно применять для прогноза продаж группы товаров, схожих по характеристикам и близких по цене.
К недостаткам метода отнесу сложность учета изменения цен, влияния аукционной деятельности. Кроме того, при оценке продаж в рублях вы не можете объективно оценить долю продаж компании в отраслевой нише, поэтому рискуете потерять долю рынка. Ваши конкуренты могут этим воспользоваться и предложить товар по более низкой цене.
Мнение эксперта
Кирилл Чихачев,
генеральный директор «МЦФЭР-пресс»
До прочтения статьи я был знаком с методом в теории. Теперь, попробовав его на практике, могу сказать, что он мне понравился. Метод идеален для анализа продаж по зафиксированным показателям: количество продуктов, сбытовая мощность и пр. Его также стоит применять для малого числа продуктов: рост и падение спроса на каждый из них зависит от разных причин. Прогноз предельно понятен, логичен и точен. Однако для еще большей точности я бы учел следующие моменты.
Максимальное и минимальное значения продаж проще рассчитывать исходя из двух точек в начале и конце периодов, а не искать точки, через которые должна проходить прямая.
При прогнозировании продаж на месяц разницу верхнего и нижнего значений для оптимистичного и пессимистичного сценариев логичнее делить не на 12, а на количество месяцев внутри отрезка. Так вы более точно рассчитаете ежемесячный прирост продаж.
На сегодняшний день наука достаточно далеко продвинулась в разработке технологий прогнозирования. Специалистам хорошо известны методы нейросетевого прогнозирования, нечёткой логики и т.п. Разработаны соответствующие программные пакеты, но на практике они, к сожалению, не всегда доступны рядовому пользователю, а в то же время многие из этих проблем можно достаточно успешно решать, используя методы исследования операций, в частности имитационное моделирование, теорию игр, регрессионный и трендовый анализ, реализуя эти алгоритмы в широко известном и распространённом пакете прикладных программ MS Excel.
В данной статье представлен один из возможных алгоритмов построения прогноза объёма реализации для продуктов с сезонным характером продаж. Сразу следует отметить, что перечень таких товаров гораздо шире, чем это кажется. Дело в том, что понятие “сезон” в прогнозировании применим к любым систематическим колебаниям, например, если речь идёт об изучении товарооборота в течение недели под термином “сезон” понимается один день. Кроме того, цикл колебаний может существенно отличаться (как в большую, так и в меньшую сторону) от величины один год. И если удаётся выявить величину цикла этих колебаний, то такой временной ряд можно использовать для прогнозирования с использованием аддитивных и мультипликативных моделей.
Аддитивную модель прогнозирования можно представить в виде формулы:
где: F – прогнозируемое значение; Т – тренд; S – сезонная компонента; Е – ошибка прогноза.
Применение мультипликативныхмоделей обусловлено тем, что в некоторых временных рядах значение сезонной компоненты представляет собой определенную долю трендового значения. Эти модели можно представить формулой:
На практике отличить аддитивную модель от мультипликативной можно по величине сезонной вариации. Аддитивной модели присуща практически постоянная сезонная вариация, тогда как у мультипликативной она возрастает или убывает, графически это выражается в изменении амплитуды колебания сезонного фактора, как это показано на рисунке 1.
Рис. 1. Аддитивная и мультипликативные модели прогнозирования.
Алгоритм построения прогнозной модели
Для прогнозирования объема продаж, имеющего сезонный характер, предлагается следующий алгоритм построения прогнозной модели:
1.Определяется тренд, наилучшим образом аппроксимирующий фактические данные. Существенным моментом при этом является предложение использовать полиномиальный тренд, что позволяет сократить ошибку прогнозной модели.
2.Вычитая из фактических значений объёмов продаж значения тренда, определяют величины сезонной компоненты и корректируют таким образом, чтобы их сумма была равна нулю.
3.Рассчитываются ошибки модели как разности между фактическими значениями и значениями модели.
4.Строится модель прогнозирования:
где:
F– прогнозируемое значение;
Т
– тренд;
S
– сезонная компонента;
Е -
ошибка модели.
5.На основе модели строится окончательный прогноз объёма продаж. Для этого предлагается использовать методы экспоненциального сглаживания, что позволяет учесть возможное будущее изменение экономических тенденций, на основе которых построена трендовая модель. Сущность данной поправки заключается в том, что она нивелирует недостаток адаптивных моделей, а именно, позволяет быстро учесть наметившиеся новые экономические тенденции.
F пр t = a F ф t-1 + (1-а) F м t
где:
F ф t-
1 – фактическое значение объёма продаж в предыдущем году;
F м t
- значение модели;
а –
константа сглаживания
Практическая реализация данного метода выявила следующие его особенности:
Применение алгоритма рассмотрим на следующем примере.
Исходные данные: объёмы реализации продукции за два сезона. В качестве исходной информации для прогнозирования была использована информация об объёмах сбыта мороженого “Пломбир” одной из фирм в Нижнем Новгороде. Данная статистика характеризуется тем, что значения объёма продаж имеют выраженный сезонный характер с возрастающим трендом. Исходная информация представлена в табл. 1.
Таблица 1.
Фактические объёмы реализации продукции
|
Объем продаж (руб.) |
Объем продаж (руб.) |
||||
|
сентябрь |
сентябрь |
||||
Задача: составить прогноз продаж продукции на следующий год по месяцам.
Реализуем алгоритм построения прогнозной модели, описанный выше. Решение данной задачи рекомендуется осуществлять в среде MS Excel, что позволит существенно сократить количество расчётов и время построения модели.
1. Определяем тренд , наилучшим образом аппроксимирующий фактические данные. Для этого рекомендуется использовать полиномиальный тренд, что позволяет сократить ошибку прогнозной модели).

Рис. 2. Сравнительный анализ полиномиального и линейного тренда
На рисунке показано, что полиномиальный тренд аппроксимирует фактические данные гораздо лучше, чем предлагаемый обычно в литературе линейный. Коэффициент детерминации полиномиального тренда (0,7435) гораздо выше, чем линейного (4E-05). Для расчёта тренда рекомендуется использовать опцию “Линия тренда” ППП Excel.
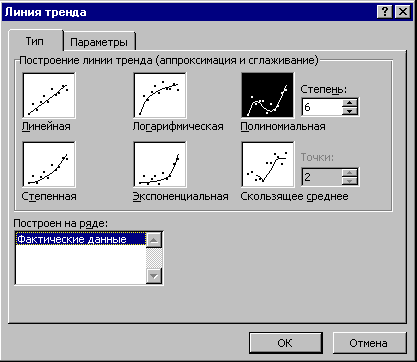
Рис. 3. Опция “Линии тренда”
Применение других типов тренда (логарифмический, степенной, экспоненциальный, скользящее среднее) также не даёт такого эффективного результата. Они неудовлетворительно аппроксимируют фактические значения, коэффициенты их детерминации ничтожно малы:
2. Вычитая из фактических значений объёмов продаж значения тренда, определим величины сезонной компоненты , используя при этом пакет прикладных программ MS Excel (рис. 4).
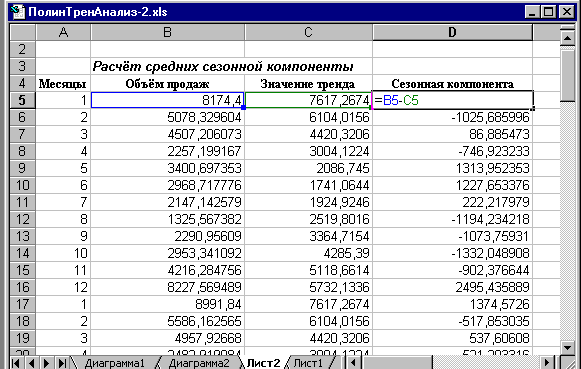
Рис. 4. Расчёт значений сезонной компоненты в ППП MS Excel.
Таблица 2.
Расчёт значений сезонной компоненты
|
Месяцы |
Объём продаж |
Значение тренда |
Сезонная компонента |
Скорректируем значения сезонной компоненты таким образом, чтобы их сумма была равна нулю.
Таблица 3.
Расчёт средних значений сезонной компоненты
|
Месяцы |
Сезонная компонента |
||||
3. Рассчитываем ошибки модели как разности между фактическими значениями и значениями модели.
Таблица 4.
Расчёт ошибок
|
Месяц |
Объём продаж |
Значение модели |
Отклонения |
Находим среднеквадратическую ошибку модели (Е) по формуле:
Е= Σ О 2: Σ (T+S) 2
где:
Т-
трендовое значение объёма продаж;
S
– сезонная компонента;
О
- отклонения модели от фактических значений
Е= 0,003739 или 0.37 %
Величина полученной ошибки позволяет говорить, что построенная модель хорошо аппроксимирует фактические данные, т.е. она вполне отражает экономические тенденции, определяющие объём продаж, и является предпосылкой для построения прогнозов высокого качества.
Построим модель прогнозирования:
Построенная модель представлена графически на рис. 5.
5. На основе модели строим окончательный прогноз объёма продаж. Для смягчения влияния прошлых тенденций на достоверность прогнозной модели, предлагается сочетать трендовый анализ с экспоненциальным сглаживанием. Это позволит нивелировать недостаток адаптивных моделей, т.е. учесть наметившиеся новые экономические тенденции:
F пр t = a F ф t-1 + (1-а) F м t
где:
F пр t - прогнозное значение объёма продаж;
F ф t-1
– фактическое значение объёма продаж в предыдущем году;
F м t
- значение модели;
а
– константа сглаживания.
Константу сглаживания рекомендуется определять методом экспертных оценок, как вероятность сохранения существующей рыночной конъюнктуры, т.е. если основные характеристики изменяются / колеблются с той же скоростью / амплитудой что и прежде, значит предпосылок к изменению рыночной конъюнктуры нет, и следовательно а ® 1, если наоборот, то а ® 0.

Рис. 5. Модель прогноза объёма продаж
Таким образом, прогноз на январь третьего сезона определяется следующим образом.
Определяем прогнозное значение модели:
F м t = 1 924,92 + 162,44 =2087 ± 7,8 (руб.)
Фактическое значение объёма продаж в предыдущем году (F ф t-1) составило 2 361руб. Принимаем коэффициент сглаживания 0.8. Получим прогнозное значение объёма продаж:
F пр t = 0,8*2 361 + (1-0.8) *2087 = 2306,2 (руб.)
Кроме того, для повышения надёжности прогноза рекомендуется строить все возможные сценарии прогноза и рассчитывать доверительный интервал прогноза.
Дмитриев Михаил Николаевич, заведующий кафедрой экономики и предпринимательства Нижегородского архитектурно-строительного университета (ННГАСУ), доктор экономических наук, профессор.
Адрес: 603000, Н. Новгород, ул. Горького, д. 142а, кв. 25.
Тел. 37-92-19 (дом) 30-54-37 (раб.)
Кошечкин Сергей Александрович, кандидат экономических наук, ст. преподаватель кафедры экономики и предпринимательства Нижегородского архитектурно-строительного университета (ННГАСУ).
Адрес: 603148, Н. Новгород, ул. Чаадаева, д. 48, кв. 39.
Тел. 46-79-20 (дом) 30-53-49 (раб.)
Практически в любой сфере деятельности, от экономики до инженерии, существует востребованность предсказать результат того или иного действия, получить значения и приблизительные данные. В этом направлении есть масса различного софта. И большинство этого программного обеспечения имеет платные функции.
Табличный процессор Microsoft имеет в своем программном обеспечении мощный инструмент для прогнозирования, который позволяет построить целый ряд различных моделей и с легкостью на практике применять различные методы. При этом в большинстве случаев этот инструмент дает более достоверные результаты, чем у платных программ. Как и каким образом? Давайте разберемся.
Прогнозирование – поиск темпов развития и получаемого результата относительно исходных данных в конкретное время.
Рассмотрим несколько способов, которые могут дать прогнозированный результат:
1. Линия тренда
Линия тренда – графическое отображение прогнозирования за счет экстраполяции. Звучит заумно? На практике все проще.
Давайте попробуем спрогнозировать сумму доходов компании через 36 месяцев на основе показателей за прошлые 12 лет.
Построим точечную диаграмму на основе исходных данных компании, а именно ее прибыль в течение всех 12 лет. Запишем исходные данные по прибыли в таблицу, выделим все ее поля и перейдем в меню «Вставка» - «Диаграмма» и выберем точечный вид диаграммы.
Для построения линии тренда выберем любую точку на диаграмме, откроем контекстное меню правой клавишей мышки и выберем из списка «Добавить линию тренда...». В появившемся меню выбора аппроксимации выберем тип «Линейная».
Произведем небольшие настройки формата линии: «Прогноз» установим на три года, вписываем «3.0», и укажем, чтобы показывалась величина достоверности и само уравнение на диаграмме.

По построенной линии тренда можем спрогнозировать доход через три года – он будет более 4500 тыс. руб. Достоверность прогнозирования принято считать верным при «0.85» ед. Эффективность прогнозирования не будет успешным, если период будет превышать 30% от периода базы.

2. Использование оператора ПРЕДСКАЗ
Также в наборе функций программы есть ряд стандартных фунций создания прогноза. Одним из таких является оператор «ПРЕДСКАЗ», синтаксис которого таковой: «=ПРЕДСКАЗ(X;известные_значения_y;известные значения_x)».
Аргумент «Х», исходя из нашей таблицы, это искомый год для прогнозирования. «Значения у» - прибыль за прошлое время. «Значения х» - года, в течение которых были собраны данные.
Узнаем, на основе уже полученных данных прогноз на следующий год с помощью оператора «ПРЕДСКАЗ». Для этого вставим в ячейку прибыли на 2018 год с помощью мастера функций оператор «ПРЕДСКАЗ».

В появившемся диалоговом окне укажем все исходные данные, согласно описанию выше.

Полученный результат совпадает с результатом предыдущего метода, поэтому можно считать прогнозирование прибыли достоверным. Для визуального подтверждения можем построить диаграмму.

Еще одним статическим оператором, который можно использовать для прогнозирования, является оператор «ТЕНДЕНЦИЯ» со следующим синтаксисом: «=ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])». Аргументы оператора идентичны аргументам оператора «ПРЕДСКАЗ».
Попробуем провести прогнозирование на следующий год, используя оператор «ТЕНДЕНЦИЯ». В новую ячейку вставим функцию из мастера функций.

Заполняем аргументы исходными данными и убеждаемся, что очередной метод прогнозирования прекрасно справляется со своей задачей – его результат схож с результатами прошлых шагов и является достоверным.

4. Использование оператора РОСТ
Аналогичным методом для прогноза данных является функция «РОСТ», за исключением того, что он использует при расчете прогноза экспоненциальную зависимость, в отличие от предыдущих методов, которые использовали линейную. Его аргументы идентичны аргументам оператора «ТЕНДЕНЦИЯ».

Как и в предыдущих шагах, вставляем в новую ячейку функцию «РОСТ», заполняем аргументы исходными данными и сравниваем результат прогнозирования. Он также дает достоверные данные, схожие с предыдущими.

5. Использование оператора ЛИНЕЙН
Другой оператор, который может спрогнозировать результат на определенный период времени, оператор «ЛИНЕЙН», который основан на линейном приближении. Его синтаксис схож с прошлыми операторами: «=ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])».
Вставим новую функцию в ячейку с прогнозированным годом и заполним аргументы.
Аппроксимация функции нескольких независимых переменных (множественная регрессия) – очень интересная, имеющая огромное практическое значение задача! Если научиться ее решать, то можно стать почти волшебником, умеющим делать очень достоверные прогнозы...
Результатов различных процессов на основе данных предыдущих периодов времени. В этой статье мы рассмотрим прогнозирование в Excel при помощи очень мощного и удобного инструмента — встроенных статистических функций ЛИНЕЙН и ЛГРФПРИБЛ.
Не пугайтесь «умных» терминов! Все, на самом деле, не так страшно, как кажется вначале! Не пожалейте время и прочтите эту статью внимательно до конца. Умение применять на практике эти функции существенно увеличит ваш «вес» как специалиста в глазах коллег, руководителей и в своих собственных глазах!
В одной из самых популярных статей этого блога подробно рассказано об (рекомендую прочесть). Но в реальных жизненных процессах результат, как правило, зависит от многих независимых друг от друга факторов (переменных). Как выявить и учесть все эти факторы, связать их воедино и на основании накопленных статистических данных спрогнозировать расчетный конечный результат для некоего нового набора исходных параметров? Как оценить достоверность прогноза и степень влияния на результат каждой из переменных? Ответы на эти и другие вопросы – далее в тексте статьи.
Что можно научиться прогнозировать? Очень многое! В принципе, можно научиться прогнозировать любые самые разнообразные результаты процессов в повседневной жизни и работе. Всегда, когда возникает вопрос: «А что будет, если…?» зовите на помощь Excel, рассчитывайте прогноз и проверяйте его достоверность!
Можно научиться прогнозировать зависимость прибыли от цены и объемов продаж любого товара.
Можно научиться прогнозировать зависимость цены автомобилей на вторичном рынке от марки, мощности, комплектации, года выпуска, количества предыдущих владельцев, пробега.
Можно научиться устанавливать зависимость объемов продаж товаров от затрат на различные виды рекламы.
Можно научиться выполнять прогнозирование в Excel стоимости наборов любых услуг в зависимости от их состава и качества.
В производстве, используя косвенные простые параметры, можно научиться прогнозировать трудоемкость и объем выпускаемой продукции, потребление материалов и энергоресурсов, и т.д.
Прежде чем начать решать практическую задачу, хочу обратить внимание на один весьма важный момент. Научиться выполнять прогнозирование в Excel с использованием вышеназванных функций ЛИНЕЙН и ЛГРФПРИБЛ технически не очень сложно. Гораздо сложнее научиться анализировать процесс, приводящий к результату и находить простые факторы, влияющие на него. При этом желательно (но не обязательно) понимать — КАК зависит результат (функция) от каждого из факторов (переменных). Линейная это зависимость или может быть степенная или какая-нибудь другая? Понимание физического смысла процесса поможет вам правильно выбрать переменные. Подбор аппроксимирующей функции следует производить при полном понимании логики и смысла процесса, приводящего к результату.
1. Четко формулируем название и единицу измерения интересующего нас результата процесса. Это и есть искомая функция — y , аналитическое выражение которой мы будем определять с помощью MS Excel.
В примере, представленном чуть ниже, y — это срок изготовления заказа в рабочих днях.
2. Производим анализ процесса и выявляем факторы — аргументы функции — x 1 , x 2 , ... x n — наиболее сильно на наш взгляд влияющие на результат – значения функции y . Внимательно назначаем единицы измерений для переменных.
В примере это:
x 1 — суммарная длина всех прокатных профилей в метрах, из которых изготавливается заказ
x 2 — общая масса всех прокатных профилей в килограммах
x 3 — суммарная площадь всех листов в метрах квадратных
x 4 — общая масса всех листов в килограммах
3. Собираем статистику – фактические данные – в виде таблицы.
В примере – это фактические данные о металлопрокате и фактических сроках выполненных ранее заказов.
Очень важно при выборе переменных x 1 , x 2 , ... x n учесть их доступность. То есть, значения этих факторов должны быть у вас в виде достоверных статистических данных. Очень желательно, чтобы получение значений статистических данных было простым, понятным и нетрудоемким процессом.
Переходим непосредственно к рассмотрению примера.
Небольшой участок завода производит строительные металлоконструкции. Входным сырьем является листовой и профильный металлопрокат. Мощность участка в рассматриваемом периоде времени неизменна. В наличии есть статистические данные о сроках изготовления 13-и заказов (k =13) и количестве использованного металлопроката. Попробуем найти зависимость срока изготовления заказа от суммарной длины и массы профильного проката и суммарной площади и массы листового проката.
В рассмотренном примере срок изготовления заказа напрямую зависит от мощности производства (люди, оборудование) и трудоемкости выполнения технологических операций. Но детальные технологические расчеты очень трудоемки и, соответственно, длительны и дороги. Поэтому в качестве аргументов функции выбраны четыре параметра, которые легко и быстро можно посчитать при наличии спецификации металлопроката, и которые косвенно влияют на результат – срок изготовления. В результате анализа была установлена сильнейшая связь между изменениями исходных данных и результатами процесса изготовления металлоконструкций.
Примечательно, что найденная зависимость связывает в одной формуле параметры с различными единицами измерения. Это нормально. Найденные коэффициенты не являются безразмерными. Например, размерность коэффициента b – рабочие дни, а коэффициента m 1 – рабочие дни/м.
1. Запускаем MS Excel и заполняем ячейки B4...F16 таблицы Excel исходными статистическими данными. В столбцы пишем значения переменных x i и фактические значения функции y , располагая данные, относящиеся к одному заказу в одной строке.

2. Так как функции ЛИНЕЙН и ЛГРФПРИБЛ — функции выводящие результаты в виде массива , то их ввод имеет некоторые особенности. Выделяем область размером 5×5 ячеек — ячейки I9...M13. Количество выделенных строк всегда — 5, а количество столбцов должно быть равно количеству переменных x i плюс 1. В нашем случае это: 4+1=5.
3. Нажимаем на клавиатуре клавишу F2 и набираем формулу
в ячейках I9...M13: =ЛИНЕЙН(F4:F16;B4:E16;ИСТИНА;ИСТИНА)
4. После набора формулы необходимо для ее ввода нажать сочетание клавиш Ctrl+Shift+Enter. (Знак «+» нажимать не нужно, в записи он означает, что клавиши нажимаются последовательно при удержании нажатыми всех предыдущих.)
5. Считываем результаты работы функции ЛИНЕЙН в ячейках I9...M13.
Карту, поясняющую значения каких параметров в каких ячейках выводятся, я расположил в ячейках I4...M8 для удобства чтения сверху над массивом значений.
Общий вид уравнения аппроксимирующей функции y , представлен в объединенных ячейках I2...M2.

Значения коэффициентов b , m 1 , m 2 , m 3 , m 4 считываем соответственно
в ячейке M9: b =4,38464164
в ячейке L9: m 1 =0,002493053
в ячейке K9: m 2 =0,000101103
в ячейке J9: m 3 =-0,084844006
в ячейке I9: m 4 =0,002428953
6. Для определения расчетных значений функции y — срока изготовления заказа — вводим формулу
в ячейку G4: =$L$9*B4+$K$9*C4+$J$9*D4+$I$9*E4+$M$9 =5,0
y =b +m 1 *x 1 +m 2 *x 2 +m 3 *x 3 +m 4 *x 4
7. Копируем эту формулу во все ячейки столбца от G5 до G17 «протягиванием» и сверяем расчетные значения с фактическими. Совпадение очень хорошее!
8. Предварительные действия все выполнены. Уравнение аппроксимирующей функции y найдено. Пробуем выполнить прогнозирование в Excel срока изготовления нового заказа. Вписываем исходные данные.
8.1. Длину прокатных профилей по проекту x 1 в метрах пишем
в ячейку B17: 2820
8.2. Массу прокатных профилей x 2 в килограммах пишем
в ячейку C17: 62000
8.3. Площадь листового проката, используемого в новом заказе по проекту, x 3 в метрах квадратных заносим
в ячейку D17: 110,0
8.4. Общую массу листового проката x 4 в килограммах вписываем
в ячейку E17: 7000
9. Расчетный срок изготовления заказа y в рабочих днях считываем
в ячейке G17: =$L$9*B17+$K$9*C17+$J$9*D17+$I$9*E17+$M$9 =25,4
Прогнозирование в Excel выполнено. На основе статистических данных мы рассчитали предположительный срок выполнения нового заказа — 25,4 рабочих дней. Остается выполнить заказ и сверить фактическое время с прогнозным.
Мы не будем погружаться глубоко в дебри статистических терминов и расчетов, но некоторых практических аспектов все же придется коснуться.
Обратимся к другим данным в массиве, которые вывела функция ЛИНЕЙН.
Во второй строке массива в ячейках I10…M10 выведены стандартные ошибки se 4 , se 3 , se 2 , se 1 , se b для расположенных выше в первой строке массива соответствующих коэффициентов уравнения аппроксимирующей функции m 4 , m 3 , m 2 , m 1 , b .
В третьей строке в ячейке I11 выведено значение коэффициента множественной детерминации r 2 , а в ячейке J11 — стандартная ошибка для функции — se y .
В четвертой строке в ячейке I12 находится, так называемое F -наблюдаемое значение, а в ячейке J12 — df – количество степеней свободы.
Наконец, в пятой строке в ячейках I13 и J13 соответственно размещены ss reg — регрессионная сумма квадратов и ss resid — остаточная сумма квадратов.
На что следует в регрессионной статистике обратить особое внимание? Что для нас наиболее важно?
1. На сколько достоверно прогнозирует срок изготовления полученное уравнение функции y ? При высокой достоверности аппроксимации значение коэффициента детерминации r 2 близко к максимуму — к 1! Если r 2 <0,7…0,8, то различия между фактическими и расчетными значениями функции будут значительными, и применять полученную формулу для прогнозирования, скорее всего, нельзя.
В нашем примере r 2 =0,999388788. Это означает, что найденное уравнение функции y чрезвычайно точно определяет срок изготовления заказа по четырем входным данным. Вышесказанное подтверждается сравнительным анализом значений в ячейках F4…F16 и G4…G16 и указывает на существенную зависимость между сроком изготовления и данными о входящем в заказ металлопрокате.
2. Определим важность и полезность каждой из четырех переменных x 1 , x 2 , x 3 , x 4 в полученной формуле с помощью, так называемой, t -статистики.
2.1. Рассчитываем t 4 , t 3 , t 2 , t 1 , соответственно
в ячейке I16: t 4 = I9/I10 =26,44474886
в ячейке J16: t 3 = J9/J10 =-11,79198416
в ячейке K16: t 2 = K9/K10 =3,76748771
в ячейке L16: t 1 = L9/L10 =3,949105515
t i = m i / se i
2.2. Вычисляем двустороннее критическое значение t крит с уровнем достоверности α =0,05 (предполагается 5% ошибок) и количеством степеней свободы df =8
в ячейке M16: t крит =СТЬЮДРАСПОБР(0,05; J12) =2,306004133
Так как для всех t i справедливо неравенство | t i |> t крит , то это означает, что все выбранные переменные x i полезны при расчете сроков изготовления заказов – y .
Наиболее значимой переменной при прогнозировании в Excel сроков изготовления заказов y является x 4 , так как | t 4 |>| t 3 |>| t 1 |>| t 2 | .
3. Не является ли случайным полученное значение коэффициента детерминации r 2 ? Проверим это, используя F -статистику (распределение Фишера), которая характеризует «неслучайность» высокого значения коэффициента r 2 .
3.1. F -наблюдаемое значение считываем
в ячейке I12: 3270,188104
3.2. F -распределение имеет степени свободы v 1 и v 2 .
v 1 = k — df -1 =13-8-1=4
v 2 = df =8
Рассчитаем вероятность получения значения F -распределения большего, чем F -наблюдаемое
в ячейке I12: =FРАСП(I12;4;J12) =6,97468*10 -13
Так как вероятность получения большего значения F -распределения, чем наблюдаемое чрезвычайно мала, то из этого следует вывод — найденное уравнение функции y можно применять для прогнозирования сроков изготовления заказов. Полученное значение коэффициента детерминации r 2 не является случайным!
Применение функции MS Excel ЛГРФПРИБЛ почти не отличается от работы с функцией ЛИНЕЙН кроме вида уравнения искомой функции, которое принимает для рассмотренного примера следующий вид:
y =b *(m 1 x1 ) *(m 2 x2 )*(m 3 x3 )*(m 4 x4 )
Статистика множественной регрессии, которую рассчитывает функция ЛГРФПРИБЛ, базируется на линейной модели:
ln (y )=x 1 *ln (m 1 )+x 2 *ln (m 1 )...+x n *ln (m n )+ln (b )
Это означает, что значения, например, se i нужно сравнивать не с m i , а с ln (m i ) . (Подробнее об этом почитайте в справке MS Excel.)
Если в результате использования функции ЛГРФПРИБЛ коэффициент детерминации r 2 окажется ближе к 1, чем при использовании функции ЛИНЕЙН, то применение аппроксимирующей функции вида
y =b *(m 1 x 1 )*(m 2 x 2 )…*(m n x n ),
несомненно, является более целесообразным.
Если прогнозное значение функции y находится вне интервала фактических статистических значений y , то вероятность ошибки прогноза резко возрастает!
Для обеспечения высокой точности прогнозирования в Excel необходима точная и обширная статистическая база данных – информация об известных из практики результатах процессов. Но, даже имея в наличии такую базу, вы не будете застрахованы от ложных предположений и выводов. Процесс прогнозирования коварен и полон неожиданностей! Помните об этом всегда! Глубже вникайте в суть прогнозируемого процесса. Тщательней относитесь к выбору и назначению переменных. На полученные результаты всегда смотрите через «очки скептика». Такой подход поможет избежать серьезных ошибок в важных вопросах.
Для получения информации о выходе новых статей и для скачивания рабочих файлов программ прошу вас подписаться на анонсы в окне, расположенном в конце статьи или в окне вверху страницы.
Отзывы, вопросы и замечания, уважаемые читатели, пишите в комментариях внизу страницы.
ПРОШУ уважающих труд автора СКАЧАТЬ файл ПОСЛЕ ПОДПИСКИ на анонсы статей!
Условное форматирование (5)
Скачать файл, используемый в видеоуроке:
{"Bottom bar":{"textstyle":"static","textpositionstatic":"bottom","textautohide":true,"textpositionmarginstatic":0,"textpositiondynamic":"bottomleft","textpositionmarginleft":24,"textpositionmarginright":24,"textpositionmargintop":24,"textpositionmarginbottom":24,"texteffect":"slide","texteffecteasing":"easeOutCubic","texteffectduration":600,"texteffectslidedirection":"left","texteffectslidedistance":30,"texteffectdelay":500,"texteffectseparate":false,"texteffect1":"slide","texteffectslidedirection1":"right","texteffectslidedistance1":120,"texteffecteasing1":"easeOutCubic","texteffectduration1":600,"texteffectdelay1":1000,"texteffect2":"slide","texteffectslidedirection2":"right","texteffectslidedistance2":120,"texteffecteasing2":"easeOutCubic","texteffectduration2":600,"texteffectdelay2":1500,"textcss":"display:block; padding:12px; text-align:left;","textbgcss":"display:block; position:absolute; top:0px; left:0px; width:100%; height:100%; background-color:#333333; opacity:0.6; filter:alpha(opacity=60);","titlecss":"display:block; position:relative; font:bold 14px \"Lucida Sans Unicode\",\"Lucida Grande\",sans-serif,Arial; color:#fff;","descriptioncss":"display:block; position:relative; font:12px \"Lucida Sans Unicode\",\"Lucida Grande\",sans-serif,Arial; color:#fff; margin-top:8px;","buttoncss":"display:block; position:relative; margin-top:8px;","texteffectresponsive":true,"texteffectresponsivesize":640,"titlecssresponsive":"font-size:12px;","descriptioncssresponsive":"display:none !important;","buttoncssresponsive":"","addgooglefonts":false,"googlefonts":"","textleftrightpercentforstatic":40}}











